Advancing Compositional Awareness in CLIP with Efficient Fine-Tuning


Abstract
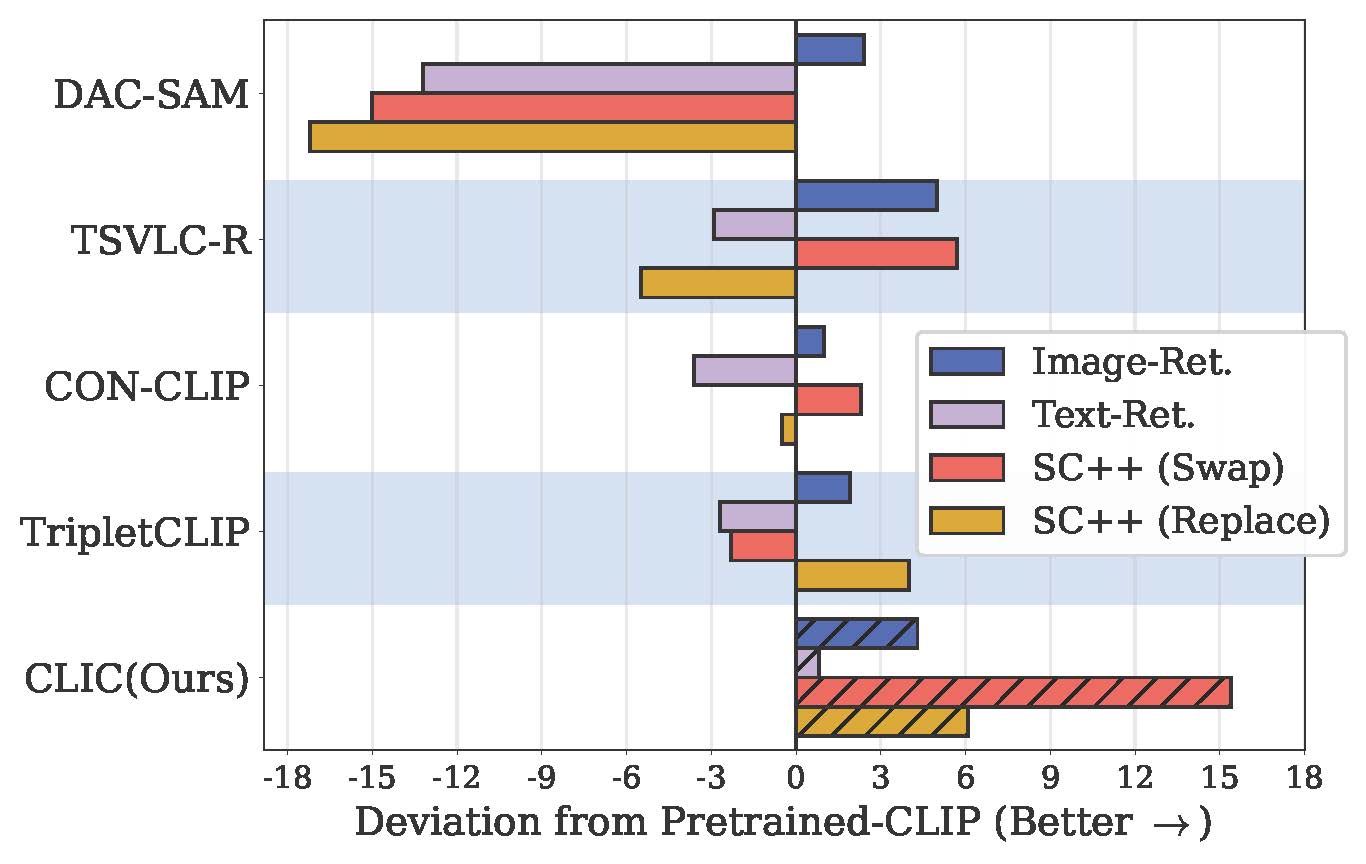
Vision-language models like CLIP have demonstrated remarkable zero-shot capabilities in classification and retrieval. However, these models often struggle with compositional reasoning – the ability to understand the relationships between concepts. A recent benchmark, SugarCrepe++[5], reveals that previous works on improving compositionality have mainly improved lexical sensitivity but neglected semantic understanding. In addition, downstream retrieval performance often deteriorates, although one would expect that improving compositionality should enhance retrieval. In this work, we introduce CLIC (Compositionally-aware Learning in CLIP), a fine-tuning method based on a novel training technique combining multiple images and their associated captions. CLIC improves compositionality across architectures as well as differently pre-trained CLIP models, both in terms of lexical and semantic understanding, and achieves consistent gains in retrieval performance. This even applies to the recent CLIPS[4], which achieves SOTA retrieval performance. Nevertheless, the short fine-tuning with CLIC leads to an improvement in retrieval and to the best compositional CLIP model on SugarCrepe++. All our models and code are available on GitHub.
How does CLIC work?
CLIC fine-tunes the text-encoder in CLIP models by leveraging already available high-quality captioned datasets like PixelProse[6] or common text-image datasets like Laion[7], which we recaption using CogVLM[8]. Using a novel technique of combining images and captions allows us to generate positives as well as hard-negatives with minimal additional overhead, e.g., we do not require an LLM for generating hard-negatives, nor do we need to generate synthetic images.
Data generation scheme for CLIC

What does CLIC offer?
- Improves compositionality with negligible decay in downstream zero-shot classification.
- Improves differently pre-trained CLIP-like models.
- Works with a variety of high-quality image-caption paired datasets.
- Consistent improvement in image and text-retrieval by fine-tuning on a small amount of data.
Want to use compositionally aware CLIC models?
See CLIC-HuggingFace. Here is a sample code for CLIC fine-tuned CLIP-ViT-L-14 model.
import torch
from PIL import Image
import open_clip
model, _, image_processor = open_clip.create_model_and_transforms('hf-hub:nmndeep/CLIC-ViT-L-14-224-PixelProse')
model.eval()
image = image_processor(Image.open(urlopen(
'IMAGE_URL'))).unsqueeze(0)
tokenizer = open_clip.get_tokenizer('hf-hub:nmndeep/CLIC-ViT-L-14-224-PixelProse')
texts= ["class1", "class2", "class3", "class4"]
text = tokenizer(texts)
with torch.no_grad(), torch.autocast("cuda"):
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
idx = torch.argmax(text_probs)
print("Output label:", texts[idx])
- Radford et al. "Learning Transferable Visual Models From Natural Language Supervision." In ICML, 2021.
- Li et al. "An Inverse Scaling Law for CLIP Training". In NeurIPS, 2023.
- Sun et al. "Eva-clip: Improved training techniques for clip at scale" In arXiv, 2023.
- Liu et al. "Clips: An enhanced clip framework for learning with synthetic captions." In arXiv, 2024.
- Dumpala et al., "Sugarcrepe++ dataset: Vision-language model sensitivity to semantic and lexical alterations". In NeurIPS, 2024.
- Singla et al. "From pixels to prose: A large dataset of dense image captions" In arXiv, 2024.
- Schuhmann et al. "Laion-5b: An open large-scale dataset for training next generation image-text models" In NeurIPS, 2022.
- Wang et al. "Cogvlm: Visual expert for pretrained language models" In NeurIPS, 2024.